Neural networks are flexible and diverse tools that can be applied in many situations, such as classification or regression. There are many different structural variations, which may be able to accommodate different inputs and are suited to different problems, and the design of these was historically inspired by the neural structure of the human brain (hence the name).
A full and comprehensive introduction into the mathematics of neural networks is well beyond the scope of this workshop - however, there are many freely available online courses, which provide an introduction for beginners.
For a crash course see, this video, for a more complete resource see the excellent deeplearningbook.org.
The aim of this blog post is to work through the practicalities of creating a neural network for classification of fix-length vectors in PyTorch. This will be a simple feed-forward network, used for the fairly trivial problem of identifying the author of a tweet.
This should lay the foundations for the understanding required to apply PyTorch to more complex, scientific problems.
Requirements
This section contains some brief details of the requirements for installating PyTorch.
Pytorch is a Python module with support for both versions 2 and 3 of the language.
If you do not already have Python installed, it can be easily installed via and good package manager (apt-get for Ubuntu, yum for RHEL, zypper for SUSE, rpm for Fedora, Homebrew or MacPorts for OS X).
It is also recommended to install a Python package manager, such as conda or pip, as this will aid in this installation of other .
The material in this blog post assumes the use of Python 3, though only minor modifications would be required to apply this material in Python 2.
Naturally this also needs pytorch.
Pytorch can be installed either from source or via a package manager using the instructions on the website - the installation instructions will be generated specific to your OS, Python version and whether or not you require GPU acceleration.
If you desire GPU-accelerated PyTorch, you will also require the necessary CUDA libraries.
Alternatively there is a virtual machine for VirtualBox, please download feeg6003_Pytorch_new.ova.
Preprocessing
As previously stated, the aim will be to identify the author of a tweet using only the contents.
The most up-to-date approach for this particular problem (text classification) would probably be a recursive neural network, however, as it is a better introduction we will work with the simpler feed-forward neural network.
The feed-forward neural network takes a vector of fixed length as an input and outputs another vector of arbitrary fixed length.
While the character number is limited, a tweet has a variable number of words, so we cannot use the tweet as is.
Some preprocessing must be done to convert a chunk of text into a fixed-length numerical vector.
We will start by stemming the words contained (especially) and removing stop words to reduce the amount of noise in the data.
Stop words are words that are considered too common to provide much information. Here are some stopwords used by other programs, the list we use is much shorter;
a able about across after all almost also am among an and any are as at be because been but by can cannot could
dear did do does either else ever every for from get got had has have he her hers him his how however i if in into
is it its just least let like likely may me might most must my neither no nor not of off often on only or other our
own rather said say says she should since so some than that the their them then there these they this tis to too
twas us wants was we were what when where which while who whom why will with would yet you your
Any word matching this list needs to be removed - the full version can be found in a csv file in this repository hosted on BitBucket.
The rest of the code is also available there, but we will put it together step by step here, which is probably easier to follow.
We start by considering the following sentences;
tweets = [['Woof', 'woof', 'I', 'promise', "I'm", 'not', 'a', 'dog'],
['ello', 'ello', 'ello', 'you', 'are', 'my', 'prime', '#suspect'],
['I', 'may', 'need', 'your', 'finger', 'prints', 'and', 'your', 'toe', 'prints'],
['Woof', 'not', 'guilty', 'woof'],
['Does', 'anyone', 'have', 'any', 'information', 'on', 'the', 'whereabouts',
'of', 'Mildred', 'I', 'need', 'her', 'toe', 'print'],
['@cooldogs', 'can', 'I', 'come', 'play', 'I', 'will', 'be', 'good', 'woof'],
['#best_detective', 'needs', 'to', 'work', 'hard', 'to', 'identify', '#suspect']]
Now using this sample lets start building a function to preprocess the words. To start with it will remove all stop words;
import copy
import csv
def preprocess_words(words, stopFileName):
with open(stopFileName, 'rt') as stopFile:
stopFileReader = csv.reader(stopFile, delimiter = " ")
for row in stopFileReader:
stopWords = set(row)
processed_words = copy.deepcopy(words)
for lineN, line in enumerate(words):
newWordN = 0
for word in line:
if str.lower(word) in stopWords:
del processed_words[lineN][newWordN]
continue
newWordN+=1
return processed_words
words_out = preprocess_words(tweets, "stop-word-list.csv")
print(words_out)
Running this code appears to execute the desired effect.
The lists returned now only contain words that are unusual and thus more useful for identifying the author.
This is a good start, now lets add something to stem the words. Stemming is a process that removes extensions from the end of a word to reduce it back to the root. This means that two similar words, say "playing" and "plays" can be identified as the same (typically the verb stem). The imported SnowballStemmer function will take care of this for us.
from nltk.stem.snowball import SnowballStemmer
def preprocess_words(words, stopFileName):
# In the same loop we can remove stop words
with open(stopFileName, 'rt') as stopFile:
stopFileReader = csv.reader(stopFile, delimiter = " ")
for row in stopFileReader:
stopWords = set(row)
processed_words = copy.deepcopy(words)
for lineN, line in enumerate(words):
newWordN = 0
for word in line:
if str.lower(word) in stopWords:
del processed_words[lineN][newWordN]
continue
newWordN+=1
stemmer = SnowballStemmer("english")
for lineN, line in enumerate(processed_words):
for wordN, word in enumerate(line):
processed_words[lineN][wordN] = stemmer.stem(word)
return processed_words
The output of this is sub-optimal.
Although the stemmer has had the desired effect in most places it has also caused some problems.
The Name "Mildred" shouldn't really be stemmed, names don't work like that.
Also, "@cooldogs" is a twitter handle, designed to be a unique identifier. We don't want to change that at all.
Further, the hashtag "#best_detective" is meant to link to a particular interest group, it is a different kind of unique identifier, so we want to keep the stemmer away from that too.
Essentially we need a mask to identify the words that the stemmer should act on.
This mask will tell the stemmer to avoid any word beginning with # or @ and any name that appears in our csv of names, which can be found on the bitbucket repository.
def preprocess_words(words, namesFileName, stopFileName):
with open(namesFileName, 'rt') as namesFile:
namesFileReader = csv.reader(namesFile, delimiter = " ")
for row in namesFileReader:
possibleNames = set(row[:-1])
with open(stopFileName, 'rt') as stopFile:
stopFileReader = csv.reader(stopFile, delimiter = " ")
for row in stopFileReader:
stopWords = set(row)
stemMask = [[1] * len(line) for line in words]
processed_words = copy.deepcopy(words)
for lineN, line in enumerate(words):
newWordN = 0
for word in line:
if word in possibleNames:
stemMask[lineN][newWordN] = 0
newWordN+=1
continue
if(word[0] == '@'or word[0] == '#'):
stemMask[lineN][newWordN] = 0
newWordN+=1
continue
if str.lower(word) in stopWords:
del processed_words[lineN][newWordN]
continue
newWordN+=1
stemmer = SnowballStemmer("english")
for lineN, (line, maskLine) in enumerate(zip(processed_words, stemMask)):
for wordN, (word, shouldStem) in enumerate(zip(line, maskLine)):
if shouldStem:
processed_words[lineN][wordN] = stemmer.stem(word)
return processed_words
The output of this is much more suitable.
Now there is just one more preprocessing step, the words need to be "bagged".
The bag of words model counts how many times each word appears in the sentence. The "bag" part refers to the indifference to word order.
To start with we will make a dictionary that maps each word in the sample to an integer, then use that to make a list of integers corresponding to each word's number.
def make_numerical(all_tweets):
word_dict = {} # Dictionary to assign a numerical ID to each word seen
for tweet in all_tweets:
for word in tweet:
if word not in word_dict.keys():
word_dict[word] = len(word_dict.keys())
# Convert each tweet to a vector, where the words have been converted to numbers
tweet_vectors = []
for tweet in all_tweets:
vector = []
for word in tweet:
vector.append(word_dict[word])
tweet_vectors.append(vector)
return tweet_vectors, word_dict
In order to bag the words we will create a list where each entry correspond to how many times the number corresponding to that index appears.
For example, a tweet that had become '[5, 0, 3, 3, 7]' should be '[1, 0, 0, 2, 0, 1, 0, 1]'.
This function will do the bagging;
def count_words(tweet_vectors, n_words):
all_counts = [] # Counts of each word for all tweets
for tweet in tweet_vectors:
tweet_counts = [0] * n_words # Counts of each word for this tweet
# Count the number of times each word is seen
for word in tweet:
tweet_counts[word] += 1
all_counts.append(tweet_counts)
return all_counts
And this is the end of our preprocessing.
If all went well running this on the test vector should yield;
all_counts=
[[2, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 3, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 1, 2, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1]]
Assuming you found this go on to the next section. If not check out the source code in the aforementioned repo.
As a further exercise, you may like to see what the output looks like for some more sentences.
quotes = [["Numero", "uno:", "the", "accidental", "treading", "the", "toe.", "It's", "an", "obvious", "one,", "but", "it", "works."],
["They", "call", "it", "a", "Royale", "with", "Cheese"],
["You", "should", "never", "underestimate", "the", "predictability", "of", "stupidity."],
["Leave", "the", "gun.", "Take", "the", "cannoli."],
["You", "talkin'", "to", "me?"],
["Well,", "do", "ya", "punk?"],
["Keep", "them", "goddamn", "babies", "off", "the", "streets!"]]
Challenge: Can you identify the sources of these wihout cheating?
There may be a small prize for the first to do so...
Neural networks
In order to train a neural network on this data we must have it's truth values.
As you may be able to guess there are only two characters in our example data;
- The "detective constable" wrote the tweets with indices 1, 2, 4, and 6.
- The "disguised dog" wrote the tweets with indices 0, 3 and 5.
So our target looks like;
target_dict = {"detective constable": 0, "disguised dog": 1}
targets=[1, 0, 0, 1, 0, 1, 0]
To start with we will use a neural net with one hidden layer with a ReLU activation function.
This is created as an extension to PyTorch's nn.Module;
import torch.nn as nn
import read_tweets
class Net(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(Net, self).__init__()
# create a linear fully connected layer
self.fc1 = nn.Linear(input_size, hidden_size)
# create a ReLU activation function
self.relu = nn.ReLU()
# create anouther linear fully connected layer
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
# begin by passing the data to a linear fully connected layer,
# this si the hidden layer
out = self.fc1(x)
# apply the activation function at the hidden layer
out = self.relu(out)
# move onto the output layer, which is also linear and fully connected
out = self.fc2(out)
return out
This is the basic form of the neural net that will learn to identify the tweets.
It will be trained using an optimiser and backpropagation.
You probably noticed that it needs to be told an input size, hidden size and the number of classes.
The input size must be the length of the vectors that will be used to train it, so len(word_dict) or len(all_counts[0]) (both of these should be the same, is it clear why?).
The hidden size is a meta parameter that you can chose. 200 is probably excessive for this example, but it works.
The number of classes is the length of the output vector.
The output vector is a vector of floats that indicate the probability that each possible author wrote the tweet.
In this case as there are two authors the number of classes is equal to 2, or equivalently len(target_dict).
Here is a diagram of the network is it is set up as described;
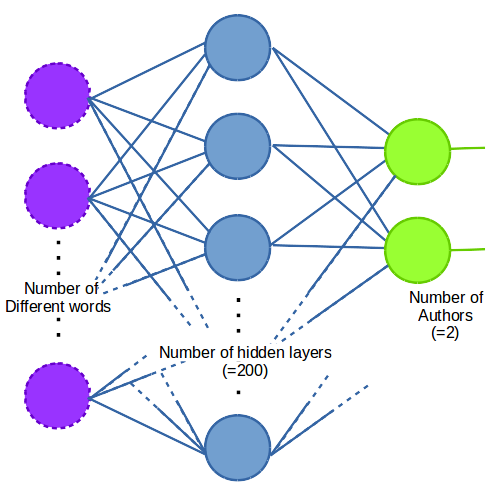
In order to run an optimiser we must have a loss function that tell us how good a particular solution is.
The loss function used here will be;
import torch
def mse_loss(output, target):
return torch.sum((output - target)**2)
It's a simple mean squared error.
With this the network can learn what a good result is.
A simple way to train the network might look like;
from torch.autograd import Variable
def train(net, criterion, optimiser, num_epochs, all_counts, targets):
for epoch in range(num_epochs):
for i, tweet in enumerate(all_counts):
# Convert to a torch tensor Variable
# torch tensor is required so the net understands it
# variable is required so that it ban be diffrentiated in the
# .backwards step
tweet = Variable(torch.FloatTensor(tweet),
requires_grad=True)
# create a list of zeros with the right shape for the target
out_target = [0] * num_classes
# put 1 into the position in the target vector that corrisponds to
# the correct target
out_target[targets[i]] = 1
out_target = Variable(torch.FloatTensor(out_target), requires_grad=True)
# reset the optimiser
optimiser.zero_grad() # zero the gradient buffer
# forward pass
output = net(tweet)
# find loss
loss = criterion(output, out_target)
# backwards pass
loss.backward()
# optimise weights according to gradient found by backpropigation
optimiser.step()
if(epoch%3==0):
# Print progress
print('Epoch %d, Loss: %.4f'%( epoch, loss))
Here the criterion is just our loss function from earlier;
The number of epochs is the number of times to go through all the examples given, 10 is a sensible number for this.
There are a variety of choices available for the optimiser, you could use;
learning_rate = 0.001
optimiser = torch.optim.Adam(net.parameters(), lr=learning_rate)
Let us use that training function to train our network.
To do this using the little example given earlier you will need to preprocess_words then make_numerical and count_words, just as before.
Then, after defining input_size, hidden_size and num_classes appropriately, create a Net object.
This can then be passed to the train function, and hopefully all will be well.
Here is a useful function to check the training of the network;
def evaluate_accuracy(net, test_tweets, test_targets, target_dict):
""" A function to print the performance of the net on a test set of tweets
Parameters
----------
net : Net
the net to be evaluated
test_tweets : 2d list of ints
The test data to be used. The top level list contains each data
point. The data points themselves are lists of ints, each one giveing
the frequency of the a word in the tweet.
test_targets : list of int
The list of targts for the test data. Each number is a target ID
target_dict : dictionary of {str:int}
a dictionary linking the target names (keys) to their
ID numbers (vaules)
"""
# Dictionary that contains {"target name": num tweets correctly identified}
correct = target_dict.fromkeys(target_dict, 0)
# Dictionary that contains {"target name": total num tweets}
total = copy.deepcopy(correct)
# inversion of the target_dict, so we can find a name from an ID
ID_dict = {v: k for k, v in target_dict.items()}
# go through the test data and check if it is correctly classified
for obs, label in zip(test_tweets, test_targets):
target_name = ID_dict[label]
obs = Variable(torch.Tensor(obs))
outputs = net(obs)
_, predicted = torch.max(outputs.data, 0)
total[target_name] += 1
correct[target_name] += (predicted == label).sum()
for target in target_dict:
percent = 100. * float(correct[target])/float(total[target])
print("Of the %d tweets by %s, %d were correctly identified."
% (total[target], target, correct[target]))
print("~~~~~~~~~~~~ %d%% match for %s ~~~~~~~~~~~~~"
% (percent, target))
If all has gone according to plan and you run the example through the training function then the evaluation function the output should be something like;
Epoch 0, Loss: 0.9610
Epoch 3, Loss: 0.7342
Epoch 6, Loss: 0.5474
Epoch 9, Loss: 0.3883
Of the 3 tweets by disguised dog, 3 were correctly identified.
~~~~~~~~~~~~ 100% match for disguised dog ~~~~~~~~~~~~~
Of the 4 tweets by detective constable, 3 were correctly identified.
~~~~~~~~~~~~ 75% match for detective constable ~~~~~~~~~~~~~
Going further
So hopefully it's all very clear up to this point.
You have created, trained and ran a neural network with PyTorch.
It works, but it's not exactly impressive, it does a bad job of observing something that is obvious.
There are many, many ways this could be improved upon.
Good next steps would include;
-
Read in many more (real) tweets to work with. 6 tweets is no where near enough data to see good results from a neural network (image processing tools typically use millions of images).
-
Divide the data into a training and testing set, so that you can check for overtraining. Or even better use cross validation.
-
Train the neural net in batches. This will lead to faster optimisation.
-
Vary the meta parameters, learning rate, number of hidden layers and number of nodes in the hidden layer.
-
Vary the loss function. It would be better is the loss function had a term in it to discourage overfitting.
-
and many other possibilities ...
For an implementation of some of these points see the repo.
Good luck with your programming!